| Dimanche 14 Decembre 2025 |
| RobotICAM
Coupe 2006
Notre Robot
Support Elec
Support Info
Support Meca
|
LA CAMERA
Les codes sources que nous avons ťcrits ne sont pas publiťs sur le site, car ils ne sont ni archivťs, ni documentťs, et difficilement exploitables.
Détection de la configuration de jeu Le principale rôle de la caméra était de déterminer la disposition des totems sur le terrain, afin de connaître les zones dans lesquelles il serait possible de se déplacer pendant le match et choisir l'une des 4 rafles à effectuer au début du match.
Les paramètres qui variaient était nombreux :
On comprend donc qu'il était impossible d'utiliser une méthode utilisant un seuil défini à l'avance pour déterminer les couleurs, car elles étaient trop dépendantes des conditions d'éclairages. On ne pouvait pas non plus utiliser une méthode travaillant sur des zones bien précises de l'image obtenue, à cause des problème des précisions du robot et des objets.
Mais ces difficultés pouvaient être contournées, soit en utilisant des outils suffisamment flexibles, soit en étant capable de les calibrer sur place. Idéalement, il aurait fallut pouvoir calibrer la caméra avant chaque début de match, par exemple en disposant une mire devant le robot. Mais comme le notre regardait "au loin" (son angle de vue était relevé au maximum pour apercevoir les totems dans le camps en face) cela aurait gêné l'équipe adverse lors de sa préparation.
Finalement, c'est la combinaisons de deux outils que nous avons employée. En effet, en arrivant sur les lieux de la compétition, nous avons constaté que la précision des tables était suffisante pour se fier aux coordonnées en pixel des objets sur l'image. De plus, nous avons eu l'occasion de faire quelques captures d'écran avant les homologations pour les déterminer avec précision.
Le premier outil était donc très simple à réaliser (il a été programmé sur place) : On appliquait un filtre à l'image pour obtenir une image monochrome où le jaune (couleur des totems) était mis en valeur : Chaque pixel de composante r, v, b recevait pour valeur (r+v)/(r+v+2*b). Multiplier la composante bleu par 2 au dénominateur permet de faire disparaître le blanc.
Exemple d'image où l'on a fait ressortir la jaune, on ne distingue plus les balles blanches :
Ensuite, le programme comparait à un seuil l'intensité des pixels dans trois zones de l'image, là où pouvaient se trouver les totems.
Mais le seuil de comparaison n'était pas défini statiquement, il variait avec l'image : Si s1, s2 et s3 était les intensités moyennes dans les trois zones, le seuil était la valeur moyenne (s1+s2+s3)/3. Ensuite, il suffisait de regarder si les zones étaient en dessous ou au dessus de ce seuil pour savoir si un totem était présent ou non. En effet, on était toujours sûr d'avoir un seul ou deux totems. Ce seuil étant défini "dynamiquement", il restait fiable même si la lumière était forte ou sombre, car les trois valeurs s1, s2 et s3 variaient dans le même sens, et leur moyenne aussi. On obtenait donc un triplet indiquant la présence des totems, que l'on comparait à une table.
Si la configuration obtenue était incohérente (par exemples à cause d'un placement du robot de mauvaise précision), nous faisions alors appel à notre second outil, un réseau de neurones.
Nous avions entraîné un réseau de neurones en consistant sa base de données d'apprentissage avec des exemples sur lesquels nous faisions varier tous les paramètres : mauvais placement, et tout les types d'éclairages possibles. Au total, une quarantaine d'exemples par configuration. Cependant, il était impossible de faire converger, car il présentait trop d'entrées (640*480*3=921600 entrées), en grande partie non porteuses d'informations. La procédure d'apprentissage, utilisant la méthode de rétropropagation du gradient de l'erreur n'arrivait pas à "faire le tri". Pour réduire les entrées, nous avons appliqué le même filtre monochrome que pour le premier outils, redimensionné l'image, et pris uniquement sa partie supérieure, la seule porteuse d'information, nous n'avions plus alors "que" 600 entrées.
Le type de
vignette après réduction (taille réelle) :
Pour encore faciliter sa convergence, nous avions retravaillé certaines images, pour lesquelles les zones entourant les totems étaient coloriées suivant deux couleurs contradictoires. Le réseau était alors "forcé" d'ignorer les entrées correspondant à ces zones. Cela a permi de faciliter la convergence lors de l'apprentissage.
Exemple d'image retravaillée :
Les valeurs des pixels issues du filtre étaient rééchelonnées sur une plage allant de -5 à 5, partie la moins linéaire de la fonction logistique utilisée par les neurones du réseau. Enfin, le réseau possédait 4 sorties binaires, et devait mettre à 1 celle correspondant à la configuration.
Nous avions ainsi obtenu un réseau apte à reconnaître la configuration de jeu quelques soit l'environnement, en tout cas à l'ICAM, ce qui était très pratique pour les tests, car cela nous permettait de positionner rapidement le robot et les éléments du jeu, même avec peu de précision. Cependant, lors de la compétition, il s'est avéré peu fiable. Heureusement, que la précision des tables était suffisante pour employer le premier outil !
Concernant ce qui se faisait chez les autres équipes, en matière de détection de totem... rien. Nous n'avons pas trouvé d'équipes repérant les totems avant le match. Toutes considéraient que les totems était présents à chaque emplacement, et les évitaient. Ces équipes devaient avoir un asservissement plus précis que le notre, où s'interdire les ¾ du terrain. Les webcams que nous avons vues servaient principalement à repérer les balles sur le terrain. Ces deux utilisations de la caméra étaient incompatibles, car repérer les totems en début de match nécessitait de regarder assez loin, tandis que trouver des balles demandait de regarder beaucoup plus bas. Ils utilisaient en général des mires avant chaque match pour les calibrer.
Pour la mise en place du système, il restait une difficulté : les totems étaient disposés après que le robots soient allumés, et avant que le match commence. Or nous ne voulions pas perdre la moindre seconde à analyser l'image après le début de la partie, car les 10 premières secondes de match sont les plus décisives. Par conséquent, le robot, après démarrage, analysait l'image provenant de la caméra à intervalle de temps régulier (5 secondes). Bien sur, les premiers résultats étaient incohérents, mais lorsque le match commençait, il reprenait le dernier résultat trouvé pour choisir sa rafle de départ.
Recommandations :
Repérage des balles
Initialement, la caméra devait avoir une tout autre fonction, celle de trouver les balles blanches sur le terrain. Ce n'est que très tardivement que nous avons pris conscience des limites de l'asservissement du robot, et que ne pas connaître les positions des totems devenait trop handicapant. Les limites de l'asservissement, notamment en vitesse, nous ont aussi amenés à utiliser un système de rafles pré-enregistrées. Dès lors, déterminer la position des totems devenait une priorité. Cela ne remettait pas en cause le développement fait dans le sens de la recherche de balles, car les deux fonctions ne se font pas au même moment, mais le manque de temps pour réaliser des test (le robot a été près pour les test une semaine avant la coupe, au lieu d'un mois comme c'était initialement prévu) et valider le travail fait a fait que ce travail a été abandonné. De toute façon, la recherche de balles n'aurait été utile qu'avec un robot suffisamment rapide pour exploiter toutes les balles déjà présentes sur le terrain, que la connaissance de la configuration de jeu permettait de connaître.
La recherche de balle peut se décomposer en 2 problèmes :
Pour trouver les pixels d'une forme nous comptions nous baser sur les couleurs, et utiliser des filtres pour différencier les balles des autres éléments : un filtre donnait une image monochrome, un seuil indiquait l'appartenance du pixel à la forme ou non, on obtenait une image bicolore.
Pour faire ressortir le blanc, différents filtres peuvent être utilisés, par exemples :
Le plus difficile est de différencier le blanc du jaune. On peut donc insister avec la composante bleu
Mais on revient toujours au problème de la valeur de seuil. On a vite laissé tomber l'utilisation d'un filtre "statique" (défini lors de la compilation du programme), et on a cherché comment obtenir un filtre dynamique qui serait différent suivant l'image analysée.
Nous avons fait quelques relevés d'image pour observer la répartition des pixels. Si on trace un graphe, qui, pour chaque intensité de pixel possible (de 0 à 255 ou de 0 à 1 selon le filtre utilisé) associe le pourcentage de pixel ayant cette intensité, on obtient ce genre de courbe :
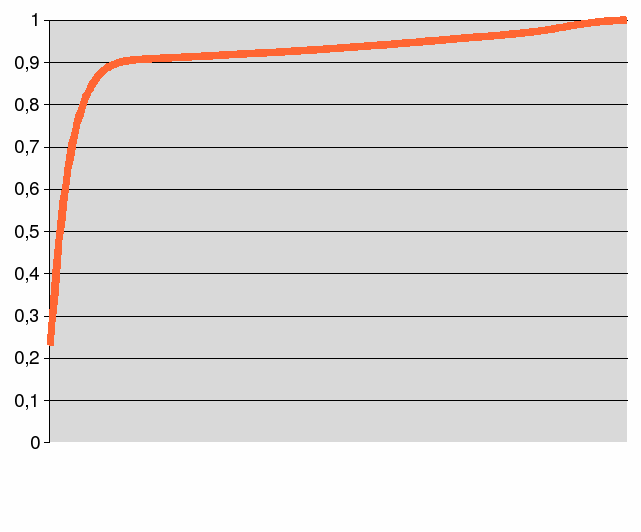
On constate que la très grande majorité des pixels est sur la gauche du graphique, elle est constituée par la couleur du plateau. Les pixels de la balle eux, sont situés quelque part à droite et sont minoritaires. Donc si on détermine un seuil situé après ce pic, on est à peu près sur de cibler les balles, l'idéal étant de couper "un peu" à droite de ce pic, car il ne contient pas tous les pixels du plateau. Mais en fonction de l'éclairage, le pic peut se déplacer vers la droite. On peut adopter une autre représentation, le pourcentage de pixels inférieure à la valeur d'abscisse (courbe des valeurs cumulées) :
L'ancien pic correspond au brusque changement de pente qui ramène la courbe vers l'horizontale. Il est alors facile de déterminer l'emplacement que doit avoir le seuil avec ce graph :
Dans les deux cas, on obtient un seuil dynamique, qui s'adapte bien à l'éclairage. On peut le calculer au début du match, ou avant chaque analyse d'image, ce qui demande alors plus de temps de traitement. Mais cela peut être indispensable si la caméra a un peu trop tendance à modifier ses coefficients de contraste et de luminosité tout seule. L'inconvénient de cette méthode est qu'elle est très lourde en calcule. De plus, il faut être sur que les pixels que l'on cherche à isoler sont minoritaires sur l'image. Si le robot s'avance très près du bord, on ne peut plus garantir de ce qu'il verra. Il faut donc toujours la coupler avec un mécanisme de reconnaissance de forme, qui validera ensuite l'objet trouvé.
Le découpage de formes Le découpage de formes se fait au moyen d'une fonction récursive. On parcourt l'image filtrée, et quand on arrive sur un pixel au dessus du seuil, on lance cette fonction qui permet de déterminer le rectangle dans lequel s'inscrit cette forme. Pour cela, la fonction se lance de manière récursive sur chacun des pixels l'entourant, eux aussi supérieurs au seuil. Elle a pour argument les limites d'un rectangle qu'elle agrandit si ses coordonnées ou les coordonnées des pixels qui l'entourent en sorte. On obtient donc le rectangle dans lequel s'inscrit la forme. On peut alors en faire une "vignette", contenant des pixels blancs ou noirs qu'il s'agira d'identifier ou non comme une balle.
La reconnaissance de forme se fait au moyen d'un réseau de neurones (et oui, encore un !). La vignette obtenue précédemment est redimensionnée avant d'être envoyée en entrée du réseau. Ce réseau possède une sortie, qui passe à 1 si une balle est reconnue, ou à 0 sinon. La détection de balle ayant été abandonnée avant que la base d'apprentissage de ce réseau soit faite (il fallait le robot final pour procéder au captures d'images), nous ne pouvons pas affirmer que cette méthode soit valable. Dans tout les cas, un système vérifiant qu'il s'agit bien d'une balle est nécessaire, car on ne peut prévoir ce que va voir la caméra. Beaucoup d'éléments peuvent avoir la bonne couleur sans être des balles, qu'il s'agisse d'éléments du robot adverse, de l'un des bords du plateau (qui sont blancs eux aussi), d'un reflet sur un totem ou même d'un élément hors du plateau.
Les inconvénients de cette méthode sont :
Image d'une balle avec un filtre très « strict » On obtient un peu n'importe quoi, suivant la disposition de l'éclairage
Une deuxième méthode a été imaginée pour réduire ce temps de traitement. Si l'on connaît la configuration de départ du robot, on sait où trouver des balles sur l'image en début de partie. On peut alors se servir des valeurs des pixels dans ces zones pour déterminer un seuil. Si on regarde les balles les plus éloignées du robot, celles qui paraîtront le moins brillante, on peut déterminer l'intensité maximum des pixels de ces balles. On est alors certains de retrouver une intensité au moins équivalente sur toutes les balles. On peut alors rechercher sur l'image les points d'intensité équivalente, découper autour d'eux une zones suffisamment large pour contenir l'éventuelle balle, et la donner à un réseau de neurones (qui travaille cette fois avec les 3 couleurs) qui l'identifiera. Là encore, la base de donnée d'apprentissage n'a pas été réalisée, et cette méthode n'a pas été testée.
Recommandations :
Le positionnement Le problème du repérage de balle se ramène pour ce qui concerne la caméra à sa calibration. En effet, il s'agit de faire correspondre un pixel d'une image prise par la caméra à ses coordonnées réelles. Il existe de nombreuses méthodes pour réaliser la calibration d'une caméra.
Points dans le champ de vision du robot :
Les mêmes points à leurs coordonnées sur l'image fournie par la caméra :
Modèle du sténopé Il s'agit d'un modèle mathématique basé sur des changements de repère (matrice de rotation, translation, homothéties). Vous pourrez trouver une documentation très précise sur : http://benallal.free.fr/these/ Ce modèle aboutit à un système de 9 équations à 9 inconnues.
En pratique : Il est donc nécessaire pour résoudre ce système d'utiliser une mire avec au moins 6 points non coplanaires. Sur ces points de la mire on connaît précisément leurs coordonnées auxquelles on peut associer facilement celles sur l'image (en pixels). Cela permet donc de résoudre ce système de 9 équations.
Inconvénients : Cette méthode demande énormément de précision. En effet la matrice (du système à résoudre) est fortement singulière. Une infime variation d'un des termes fait énormément varier la solution. Il faut donc une bonne précision au niveau des mesures ce qui n'est pas forcément évident.
Mais il existe une solution pour résoudre ce problème. Il s'agit des méthodes d'optimisation notamment celle utilisée par l'équipe de l'ESCPE : la méthode du quasi-Newton (BFGS). N'ayant eu connaissance de cette méthode que durant la compétition nous avons d'une part laisser tomber la solution du modèle du sténopé et d'autre part nous n'avons pas appliquer cette méthode d'optimisation.
Interpolations et éléments finis. Cette méthode consiste à interpoler la fonction qui permet de passer des coordonnées sur une image à celles dans la « réalité ».
En pratique : On réalise un maillage plus ou moins fin d'une image du terrain de jeu (prise par la caméra) avec des éléments géométriques simples afin d'avoir à disposition des fonctions d'interpolation simples . Il faut ensuite connaître les coordonnées réelles de chaque nŇďud afin de pouvoir déterminer les fonctions d'interpolations qui dépendent des valeurs en ces noeuds. Ainsi on peut interpoler à partir des valeurs en ces nŇďuds tout point à l'intérieur du maillage. Plus le maillage est fin plus on est précis.
Inconvénients : Cette méthode est très contraignante. En effet, il est compliqué de mesurer les coordonnées de points que l'on voit sur l'image. Pour ce faire, nous placions des petits aimants sur le plateau et prenions des photos déplaçant à chaque fois les aimant afin de les faire correspondre avec les nŇďuds du maillage de l'image.
Documentation : La documentation utilisée est celle de M. PETITJEAN.
Réseaux de neurones (encore eux !) La dernière solution, et finalement celle qui a été retenue, est celle du réseau de neurone. Cela marche un peu sur le même principe que les éléments finis c'est-à-dire qu'il faut connaître les coordonnées d'un bon nombre de points du plateau et leur correspondance en pixels.
En pratique : Nous avons utilisé une barre en fer sur laquelle nous avons collé à intervalles réguliers des aimants (chaque 10cm). Le robot sur lequel est fixé la caméra est placé sur le plateau de jeu (ou ailleurs) mais ne bougera pas pendant toute l'opération de calibration. Nous avons pu en déplaçant la règle et en prenant des clichés à chaque déplacement obtenir un ensemble de points recouvrant tout le champ de vision de la caméra.
Après traitement de toutes ces images afin de bien faire ressortir les aimants, un programme permet d'affecter à chaque aimant ces coordonnées en pixels sur l'image.
Cliché
Cliché après traitement
Connaissant les coordonnées et leurs équivalents en pixels, on a rééchelonné les dimensions sur un intervalle plus petit, [-5,5], plus adapté pour la fonction de transfert des neurones. Les deux sorties, comprises dans [0,1] étaient rééchelonnées pour correspondre aux dimensions du terrain. La précision était très liée à la taille du réseau. Le notre, avec 3 couche cachées de 10 neurones nous permettait une précision de 2 cm. Nous n'avons pas cherché à obtenir plus, car les erreurs sur les mesures étaient elles aussi importantes.
Inconvénient de toutes ces méthodes : La calibration est une opération (très) longue. sachant qu'elle est à refaire pour chaque changement de position ou infime variation de l'angle d'inclinaison de la camera il faut veiller a ce qu'elle soit bien fixée, au risque de devoir la refaire. Si nous avons opté pour la dernière solution, ce n'est pas tant pour ses qualités (à peu près précise, mais pas très rapide comparée aux autres). C'est uniquement parce que nous avons trouvé un moyen assez efficace de faire un relevé de mesures pour la mire (plus de 500 points de comparaison). Et pourtant, celui-ci reste très lourd à mettre en oeuvre. Ceci-dit, il est possible de se faire aider pour presque toutes les étapes par des personnes qui ne connaissent pas la méthode, et une des taches pouvait être faite par un programme.
Informations générales sur la caméra.
Il s'agit d'une Logitech Quickcam Pro 4000. Étant donné que le robot tourne sur du Linux il faut donc installer les drivers de la caméra pour Linux. Les sources peuvent être téléchargées sur le site suivant :
http://www.saillard.org/linux/pwc/
Il suffit donc de les compiler et de les mettre en module.
|
||||||||||||||||||||||














Copyright © 2006 RobotIcamToulouse |